Methodologies
Using Teleoscope in your research project
We originally built Teleoscope in an academic context targeting qualitative researchers. We have always had the needs of academics front and center. During our interviews and focus groups (which you can read about in our paper), our participants told us how important it was that using Teleoscope in a qualitative study could be explained to colleagues and reviewers.
This section addresses our understanding of where Teleoscope fits in the qualitative research world, but you might also find it useful to look at our examples, lessons, and How-to sections to get more insight on how Teleoscope can be used in your research project.
Topic Models
Teleoscope fits under the umbrella of topic modelling (opens in a new tab). We use pre-trained transformer embedding models from the Hugging Face (opens in a new tab) ecosystem (see BAAI/bge-m3 (opens in a new tab) in production) to provide dense vectors for your documents, then apply a variety of techniques to help you find and group documents that are closest to your idea of what a good topic is.
You can think of a "topic" as a group of documents that a computer is guessing is thematically similar (i.e., on the same topic). If you have a large group of documents that you would like categorized, you can say to a clustering algorithm, "please group these documents by how similar the topic seems to be." If you have no input into the process, that's called unsupervised topic modelling.
Teleoscope uses a semi-supervised topic modelling approach. We ask users like you to look through documents and make groups according to what they think is similar. Then, the Teleoscope algorithm will rank and group documents according to your examples.
Your own interpretation
Teleoscope attempts to support computer-assisted qualitative research by putting the values of qualitative researchers front-and-center. We wanted to reflect the process of arranging data by hand in the Teleoscope workspace. We also wanted to give qualitative researchers the feeling of really digging into their data, even though they're searching through thousands or millions of documents.
Although Teleoscope relies on a fixed embedding model for efficiency, you impose your own interpretive perspective by asking the system to rank and group documents according to what you think is similar. Ideally, it is picking up on your personal sense of thematic similarity.
That is why we call Teleoscope topics "themes" like in thematic analysis (opens in a new tab). We mean the groups that you develop in Teleoscope to be more than just categories. They are attempting to reflect an underlying intuition that you have about your data, and help reflect the way that you make sense of your data.
Managing personal bias through provenance
Of course, as researchers, we don't want to insert our own bias into our interpretations. It's a tough process to balance the helpful intuitions we have as qualitative researchers with keeping a rigorous academic lens.
That's why we built Teleosope with provenance as the foremost design metaphor. We wanted people to be able to continually re-trace their own steps, show their thought process to their colleagues, and amend it when needed. The qualitative researchers (other than ourselves) we worked with to develop Teleoscope wanted to ensure that they could track how they processed their data.
Thematic Exploration vs. Analysis
Teleoscope is for ranking, grouping, and prioritizing data. It is not a coding tool. However, it could help you with the coding process. Let's see what that means.
When you have common qualitative datasets, you might be able to look through tens, maybe hundreds, and if you had a very large research group with a lot of paid coders, a couple thousand documents. However, when you get to thousands to millions of documents, it stops being feasible or even desirable to look through your data.
Most people start relying on keywords and statistics at this point.
Overview of the Teleoscope Method
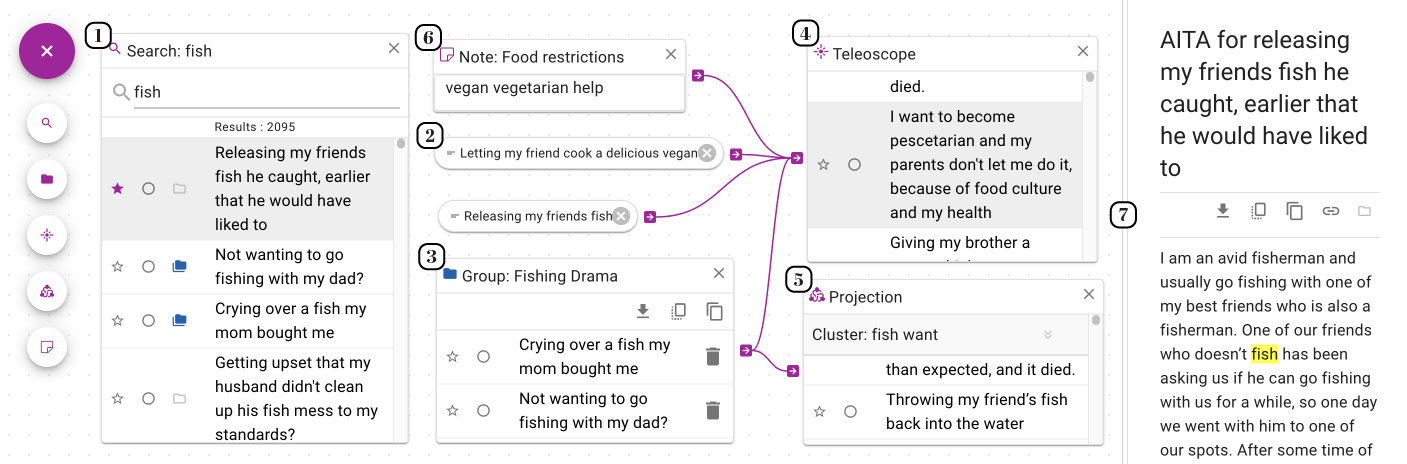 (1) Start by performing a standard keyword search to explore documents;
(2) Drag documents onto the workspace;
(3) Group documents for organization;
(4) Ranks can use documents, notes or groups as control inputs;
(5) Projections create clusters using groups as control inputs;
(6) Notes can contain arbitrary text which is also vectorized and can be used as a control input to a Teleoscope;
(7) Read documents on the sidebar as well as edit your saved items, bookmarks, and settings. Keyboard navigation through document lists and bookmarking are included for quick exploration and group creation.
(1) Start by performing a standard keyword search to explore documents;
(2) Drag documents onto the workspace;
(3) Group documents for organization;
(4) Ranks can use documents, notes or groups as control inputs;
(5) Projections create clusters using groups as control inputs;
(6) Notes can contain arbitrary text which is also vectorized and can be used as a control input to a Teleoscope;
(7) Read documents on the sidebar as well as edit your saved items, bookmarks, and settings. Keyboard navigation through document lists and bookmarking are included for quick exploration and group creation.
You can see how Teleoscope works by mixing the semantics of your control input examples. Above, we have the concept of fish mixed with the concept of vegetarianism. In the Teleoscope output, you can see that it has found documents that have to do with pescatarianism, which is a dietary choice that is like vegetarianism but you can also eat fish (opens in a new tab). Nowhere in the text does it mention vegetarianism, yet it is highly ranked in the Teleoscope output.
The Teleoscope Rank
Teleoscope ranks documents by similarity in the embedding space produced by its Hugging Face embedding model.
When multiple documents are input as controls, the Teleoscope will average the
document vectors to give you a "mix" of the different vectors. In this way, a
Teleoscope search is a search by example. You can connect many documents to
tune the Teleoscope rank to follow conceptual similarities that you imagine.
You can also vectorize your own sentences by creating a note and add it into the mix.
In this way, you are building up a visual trace of a concept that you're exploring. You can capture your own thought process by seeing which documents are feeding into the Teleoscope, and what you had to do to come up with the machine representation you were interested in.
Grouping and Projections
Grouping means that you've decided that certain documents are thematically similar whether or not the machine has. Of course, this can just be an organizational tool, but you can also use groups as inputs to Ranks and Projections. This is where the power of the system can really be seen.
A Projection produces groups of documents that the machine has clustered together as similar based on the groups you use as control inputs. It is called a projection because it performs dimensionality reduction (opens in a new tab) on the document vectors. Think "projection" like "projecting your shadow onto a wall." It's taking something higher-dimensional and creating a lower-dimensional representation of it. Teleoscope uses the UMAP (opens in a new tab) library to perform our projections and HDBSCAN (opens in a new tab) to perform our clustering.
The practical upshot is that our system will attempt to cluster the document source based on the groups you provide. You can think of it like steering a general-purpose embedding model (such as the one Teleoscope uses for document vectors) toward your specific way of thinking about your document set.